Everett Wisconsin Fast Plant Lab Report
The Effect of Artificial Selection on Wisconsin Fast Plants
The purpose for performing this lab is to model artificial selection within Wisconsin Fast Plants. As a class, we chose the characteristic of average leaf length of the plants to be selected for in which a change in the average leaf length would be predicted in the offspring from the parent generation. The research question we are trying to answer is: does the selection for the average leaf length influence the phenotypes of the offspring? The results of the experiment showed that the research question is not supported by the data that my classmates and I collected.
In the beginning of the experiment, a parent generation of fifty seven Fast Plants was grown within planting units each having four pods. In each pod a diamond wick, planting soil, fertilizer seeds, and fast plant seeds were placed respectively in this order. They were grown continuously for approximately 40 days before the offspring plants were grown. All plants, however, were place on top of a water reservoir to ensure the plants maintained ideal water levels. All plants were also under cool-white fluorescent lights to allow plants to perform metabolic process and grow. After approximately five days the average leaf lengths for each of the plants were recorded (Figure 1). The averages for the leaf lengths vary continuously from plant to plant. (Figure 1). There is no relationship shown between the average leaf length for each plant in which there is no bell curve. The average leaf lengths for the plants are heavily concentrated between four to six millimeters and between eight and ten millimeters. The outliers for this graph are the average leaf length between six and eight millimeters and from ten to twenty millimeters. (Figure 1). The most concentrated averages and the outliers are not integrated in the graph to where a pattern is shown. The data is not normally distributed because if it was, a bell curve would be shown in which the sloping sides would contain the outliers and the curve would contain the average leaf lengths that are most concentrated by the plants. Another account for why the data is skewed is because the standard deviation is 3.39 which is higher than the standard deviation for the survivors (1.26) and F1 generation (1.81). There is more variation of the data here which explains why the data is not more evenly dispersed. Even though a pattern is not depicted, the curve of the bell curve represents the mean of all the average leaf lengths for the parent generation plants which is 8.839181287.
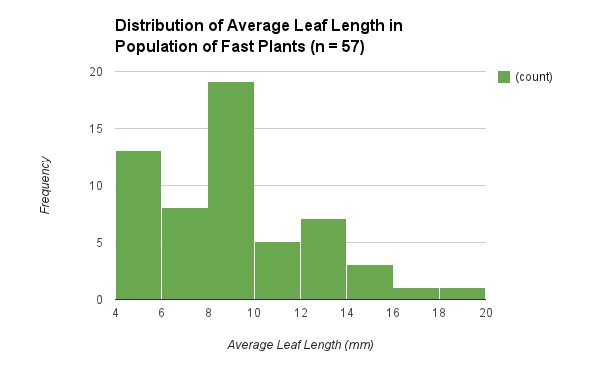 |
| Figure 1 |
From the information from figure one, it was decided by my classmates and I that the leaf lengths under 12 mm was to be selected against. To implement this selection pressure, the class trimmed the leaves of all the plants that had a leaf length of twelve millimeters and below. The outcome the my classmates and I were expecting to see in the survivor parent population were all plants with leaf lengths of twelve millimeters and over. The average leaf lengths for each plant for the survivors after selection were recorded (Figure 2). There is a significant decrease in the population of the parent population to the survivor population in which the parent population has 57 plants and the survivor population only has 8 plants. The frequency of higher average leaf length is significantly lower than in the original parent population when compared to the survivor population. To make this conclusion, the means of the parent population and the survivor population was compared. The parent population mean is 8.84 and the survivor population mean is 13.88. The average leaf length increased after the selection pressure was implemented. Because all leaf length under twelve millimeters were selected again, only leaf lengths above twelve millimeters were left. This caused a shift in the graph from eight to ten millimeters in the parent population to 13.5 millimeters to 14.5 millimeters. In addition, the dispersion and variation of the data for the survivor population is smaller than that of the parent population. This is accounted from through the standard deviations of the two populations. The standard deviation for the parent population is 3.39 but the survivor population has a standard deviation of 1.26. The smaller the standard deviation, the less variation and dispersion of the data. The standard deviation also accounts for the lack of fluctuation in the graphs because of the lack of variation and dispersion which is why the graph lacks a bell curve. On another note, the SEM of the survivor population is 0.45 and the 95% confidence interval for the survivor population is from 12.98 to 14.78. For the parent population, however, the SEM is 0.45 and the 955 confidence interval is from 7.94 to 9.74. The confidence intervals show the range of the where the means will lie if the experiment is performed again. Since the confidence intervals from the survivors population and the parent population do not overlap, I can conclude that the means for both populations are significantly different from each other. This would imply that the selection pressure that was implemented was a success.
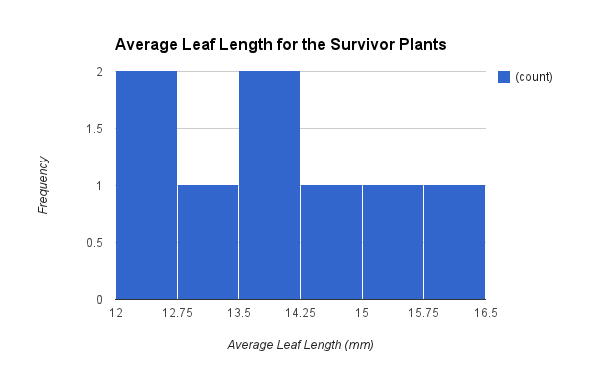 | ||
| Figure 2
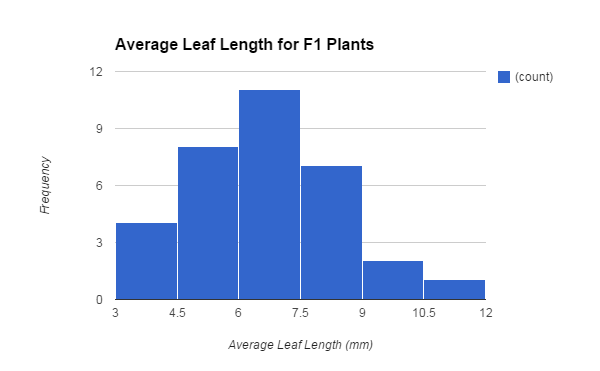
Using the survivors population, my classmates and I performed sexual reproduction with the plants by cross pollinating the plants using bee sticks. If the process is done correctly the plants will produce produced seed pods which are then used to plant the F1 generation. After letting the offspring grow for approximately nine days, we measured their leaf lengths for each plant a recorded them (figure 3).
The graph now depicts a bell curve in which the data is evenly distributed and an average leaf length can be roughly seen. The mean of the F1 generation is 6.462121212 which is different from the parent population and the survivor population in which their means were 8.84 and 13.88 respectively. The average leaf length shifted along the graph in which it is not the same as the survivor population but it is similar to the parent population in which the average leaf length now ranges from 6 millimeters to 7.5 millimeters. The means of the parent population and the F1 generation are more similar than that of the survivor population. The standard deviation for the F1 generation is 1.81 which is higher than the survivors standard deviation which is only 1.26. The standard deviation is high for the F1 generation because there were more plants in the F1 generation (33) than the survivors generation (8) which increase the variation in the plants. To ensure that the mean of the F1 generation is not similar to the survivor population, the 95% confidence intervals were compared. The definition of similar or not similar is determined through 95% confidence intervals. The null hypothesis that is used to see if the survivors generation is similar to the F1 generation for is that there is no significant difference between the mean of the original population and the mean of the F1 generation.The SEM of the original population is 0.4492766416 and the SEM for the F1 generation is 0.3146201419. These SEM’s provide the range in which the confidence interval will range based on 5% built in error if the experiment was performed again. The upper and lower confidence intervals for the original survivor population is 14.78 and 12.98 respectively. The upper and lower confidence intervals for the F1 generation is 7.091361496 and 5.832880928 respectively. These confidence intervals do not overlap at any point in time which means that is a significant different between the mean of the survivor generation and the F1 generation. The null hypothesis failed to be rejected in this situation.
|
Overall - some tense/grammar/spelling issues.
ReplyDeleteAnalysis - 16/20
- Only 1 parenthetical "(Figure 1)" is necessary. This tells the reader where to look.
- "There is no relationship shown between the average leaf length for each plant in which there is no bell curve" --> ???
- Incorrect use/interpretation of standard deviations.
- You've established there isn't a bell curve, so later phrases such as "the curve of the bell curve" become a bit nonsensical.
- Is there a reason why you didn't round that mean after a few decimal places?
- Comparing standard deviations for different populations and relating them to the graphs is misleading, since the graphs have different bin widths
- Good explanation of the 95% CI test for P gen before vs. after selection.
- "The standard deviation is high for the F1 generation because there were more plants in the F1 generation (33) than the survivors generation (8) which increase the variation in the plants" --> not sure I agree with this logic
- Why did you wait until your second 95% CI test to offer the rationale for doing so? It seems poorly timed/misplaced.
- If the 95% CIs don't overlap, shouldn't you reject the null hypothesis (which is that there is no difference in the population means?)
Discussion - 14/20
Conclusion:
- Good explanation in the first half of this paragraph, right up until...
- "I had an outcome of what I wanted the outcome of the experiment to be and the results were not matching up."
-- Need to maintain professional tone. This paragraph would be much better if you positioned your hypothesis as one founded on sound biological reasoning vs. personal preference.
- Speaking of sound biological reasoning, do you really think the trait of leaf length isn't heritable? You can entertain it as a possible hypothesis, but I don't know if that's a conclusion you're able to support based on the evidence and reasoning you offer.
- "The seeds that did not bloom could have possibly had leaves of 12 mm or higher that could have affected the results of the experiment in some way. " --> Right idea, cop-out conclusion. HOW could those other seeds have affected your data? Be specific!
Evaluation:
- Can you give a concrete example (or pose a relevant scenario) where lack of organization affected the validity of the experimental results/conclusions? Or is this just musing about lab errors in the abstract?
- Measurement error is important -- don't forget interpersonal differences, as well as the fact that we never actually calculated P generation avg leaf lengths
- Given the length of the life cycle of a Wisconsin Fast Plant, are you actually suggesting we should have done nothing other than literally watch the grass grow over the course of this months-long experiment? Nice try :)